- RNN是什么
- RNN要解决的问题
- 标准RNN存在的问题
- LSTM基本原理
- LSTM的其它变体
- RNN在目标检测方面的应用
- 参考文献
RNN是什么
RNN全称是Recurrent Neural Networks, 循环神经网络,近几年来在深度学习领域内的研究热度毫不逊与卷积神经网络CNN,尤其擅长挖掘时序或具有序列意义的数据中潜在的模式,在语音识别、机器翻译、句法分析等领域发挥了巨大的作用,同时在图像视频处理方面,也有较好的表现。而LSTM是指长短期记忆网络,属于一类具有更多优点广泛使用的RNN网络,除了LSTM之外还有GRU等更多变种。在这里单独就LSTM原理做一下总结。
学习LSTM一般都是从RNN基础开始,最经典的资料莫过于多伦多大学的Alex Graves的RNN专著《Supervised Sequence Labelling with Recurrent Neural Networks》以及提出LSTM的作者Felix Gers的博士论文《Long short-memory in recurrent neural networks》,这两个文献内容都有100多页还没有看,而是看了2015年UCSD的Zachary C.Lipton写的一篇综述文章《A Critical Review of Recurrent Neural Networks for Sequence Learning》以及Colah的一篇blog材料 《Understanding LSTM Networks》。
RNN要解决的问题
人类并非时刻都从空白的大脑开始学习和认知事物,当你阅读这篇文章时,你就是在运用以前对这些词句的含义理解等先验知识来作出认知判断,就是说神经网络应当具有信息记忆能力,也就是当前时刻的输出除了与当前输入有关,还与之前的输出有关。形象地图示表示为下图左边这样,按序列展开为右边这样。

那么问题来了,传统的马尔科夫链比如HMM就是解决这种具有时序依赖关系的模型啊。但是研究人员发现,当可能的隐层状态空间增长较大时,状态转移矩阵计算量呈指数式增长,使得处理的问题规模十分有限,无法处理长时间或长状态序列前后依赖的问题。
标准RNN存在的问题
RNN的关键点之一就是将先前的信息连接到当前的任务上对当前内容进行理解,例如预测句子“The clouds are in the ”中的横线处,很容易根据序列中前面的clouds预测到后面横线处填sky,这种前后信息的位置间隔仍然不算长,但当场景复杂一点后,比如预测句子“I grew up in France…(此处省略N多字)…I speak fluent ”,横线处的预测就需要依赖前面很远位置的信息“France”来推断此处为“French”。理论上RNN是可以处理这种长期依赖问题的,然而标准的RNN为了处理这样的场景,在进行模型训练时由于每个RNN单元都要循环多次,利用梯度下降算法极易出现梯度的消失问题。于是,LSTM解决了这样的问题。
LSTM基本原理
LSTM单元设计了类似于水阀门的一种“门”结构来控制网络的信息流,实现信息的长期记忆和短期激活,从而解决长期依赖问题。LSTM单元包括输入节点、输入门、内部状态、遗忘门、输出门组成,如图所示为一个基本的LSTM单元的示意图。

多个这样的LSTM单元顺序连接,就构成了LSTM网络。看着挺复杂,但其实分解来看也不难。首先最上面流水线通过矩阵内积“×”的方式实现遗忘门,如图3,即通过乘以0或者1使得上一时刻的记忆信息C(t-1)被遗忘或者保留。这个结构决定了从上一时刻状态C(t-1)中丢弃什么信息。

然后需要决定当前的状态C(t)中需要加入什么样的新信息。如图4,包含两部分,一个是使用sigmoid激活函数的输入门,一个是使用tanh激活函数的内部状态,这两个结构输出后做内积相乘,也就是丢弃部分旧输入信息h(t-1),产生当前新信息的状态。

然后将当前状态C(t)与旧状态C(t-1)相加得到当前的输出状态C(t),如图5。

最后,我们需要确定什么样的输出。如图6,用sigmoid函数来确定当前输入的哪个部分将输出出去。接着用tanh将当前状态C(t)哪些输出到下一时刻的输入,最后用内积相乘确定最终的输出。

综合上述分析,就可以得出一个现在常用的标准LSTM的前向训练过程:
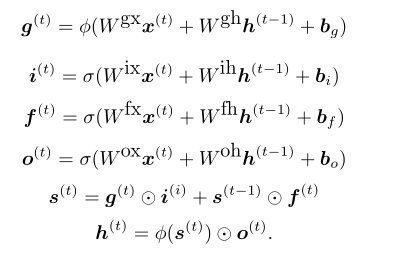
LSTM的训练算法仍然是使用梯度下降算法BPTT(Back propagation through time),详细的数学推导过程比较复杂,只用一个小的算例体验了下这个训练过程,具体细节不作详述,算例过程可以参考文章[3]。
LSTM的其它变体
上述介绍的只是使用较多的一个标准LSTM,在不同的实际应用中会有不同的变体形式。比如加入窥视孔连接(peephole connection)的LSTM如图7所示:

还有改动较大并且使用也非常多的LSTM变体门限循环单元GRU(Gated Recurrent Unit),如图8,将遗忘门与输入门合并为单一的更新门,以及其它细节改动。这种GRU比标准LSTM模型更简单。

LSTM的其它变种还有很多,Jozefowicz等人在超过一万种RNN的架构上进行了对比测试,发现在特定的深度学习任务上,有许多RNN结构比LSTM表现更好。
RNN在目标检测方面的应用
由于我本人关注较多目标检测与识别方面的进展,在学习了RNN和LSTM之际也了解了下RNN在目标检测方面的应用案例。RNN在获取目标上下文信息方面相比于CNN有独特的优势,下面是相关文章:
Bell S, Zitnick C L, Bala K, et al. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks[J]. arXiv preprint arXiv:1512.04143, 2015.
用skip pooling和 RNNlayer,在多尺度的feature map 上做roi pooling,最后一个feature map是通过rnn得到。Stewart R, Andriluka M. End-to-end people detection in crowded scenes[J]. arXiv preprint arXiv:1506.04878, 2015.
使用LSTM实现detection。Li J, Wei Y, Liang X, et al. Attentive Contexts for Object Detection[J]. arXiv preprint arXiv:1603.07415, 2016.
文章利用local(多尺度的cnn特征)和global(LSTM生成)来做目标识别。Liang M, Hu X. Recurrent convolutional neural network for object recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3367-3375.
每一层卷积后用RNN,文章引用量不大。
参考文献
[1]. Lipton Z C, Berkowitz J, Elkan C. A critical review of recurrent neural networks for sequence learning[J]. arXiv preprint arXiv:1506.00019, 2015.
[2]. Shi Yan. Understanding LSTM and its diagrams. [N/OL] https://medium.com/@shiyan/understanding-lstm-and-its-diagrams-37e2f46f1714#.txbyrhd0j.
[3]. Aidan Gomez. Backpropogating an LSTM: A Numerical Example.[N/OL] https://medium.com/@aidangomez/let-s-do-this-f9b699de31d9#.qygi8z4wx.